


Abstract
The failure to compensate for subject motion between attenuation correction scans and emission scans precludes the optimization of functional brain imaging techniques. We have developed an automated method for attenuation correction that compensates for subject motion by deriving each set of correction factors from the corresponding emission study. Methods: The technique consists of generation of an estimated skull image by filtered backprojection of the reciprocal of an emission sinogram; estimation of the thickness and radius of the skull on profiles extracted from the image; scaling the radius and thickness values to generate a model of the brain, skull, and scalp; and assignment of attenuation coefficients to the head model for generation of attenuation correction factors. Values for scale factors and tissue attenuation coefficients were determined empirically by fitting the emission-derived head model to measured transmission data in five subjects using nonlinear regression (group A). The average model parameters, across five datasets (group A), were then used to generate attenuation maps for five independent emission studies (group B). Mean-squared-error values were calculated between the measured transmission data and the two model groups. For comparison, mean squared error values were calculated between the measured transmission data and homogeneous ellipses that were manually fitted to emission images. Results: The difference between the mean squared error for groups A and B was not significant (P > 0.8), indicating that model parameters from a small group can be used for other subjects without further fitting. The mean squared error for the automated method was significantly lower than that of the ellipse method (P < 0.001). The method reduced emission image variance, resulting in a higher peak Z value in activation images. The elimination of measured transmission scans resulted in a reduction in scan time (∼15 min) and radiation exposure (∼0.5–1.6 mrem). Conclusion: We have developed an automated attenuation correction method that compensates for subject motion between scans, accurately reproduces the characteristics of the head, and eliminates the use of measured transmission data to reduce scan duration, statistical noise propagation, and radiation dose.
Imaging of cerebral blood flow by PET has played a central role in the development of our current knowledge about the spatial distribution of functional centers and neuronal networks in the human brain. The advantages of PET techniques for mapping human brain function include minimally invasive procedures to administer radiotracers and the capability to image the entire brain simultaneously. However, physical factors associated with the interaction of 511-keV annihilation photons with matter (attenuation and scatter) result in the collection of datasets that do not meet the assumptions inherent in standard analytic tomographic image reconstruction algorithms (i.e., that each measured data value represents the integral of the radionuclide quantity along a line through the object being imaged). Photon attenuation in the human head results in nonuniform signal loss in the line integrals that pass through the head (maximum loss is a factor of ∼6). To overcome this limitation, transmission scans are obtained using either γ-ray or 511-keV annihilation photon sources to measure the signal loss that occurs along each line integral through the brain during the PET imaging study. This information is then used to generate correction factors for the measured PET data, enabling the reconstruction of quantitative images of radiotracer concentrations and, hence, cerebral blood flow. To reduce the overall PET imaging study duration as well as the radiation dose, a short (<30 min) transmission scan is typically acquired. Such count-limited transmission scans result in attenuation correction factors that have significant statistical noise, which subsequently propagates as added noise in the reconstructed PET images (1). Subject motion between the time of the transmission scan and the multiple blood flow scans in a brain activation imaging sequence also leads to unpredictable artifacts in the reconstructed PET images (1). Although realignment between blood flow images in a series is rigorously addressed by most investigators, the problem of misalignment between blood flow data and attenuation correction factors has been largely ignored. To overcome these limitations, we have developed an automated attenuation correction method (2) that compensates for subject motion between scans, accurately reproduces the characteristics of the head, and eliminates the use of measured transmission data to reduce scan duration, statistical noise, and radiation dose. This article describes in detail the implementation and validation of this method.
MATERIALS AND METHODS
Description of Algorithm
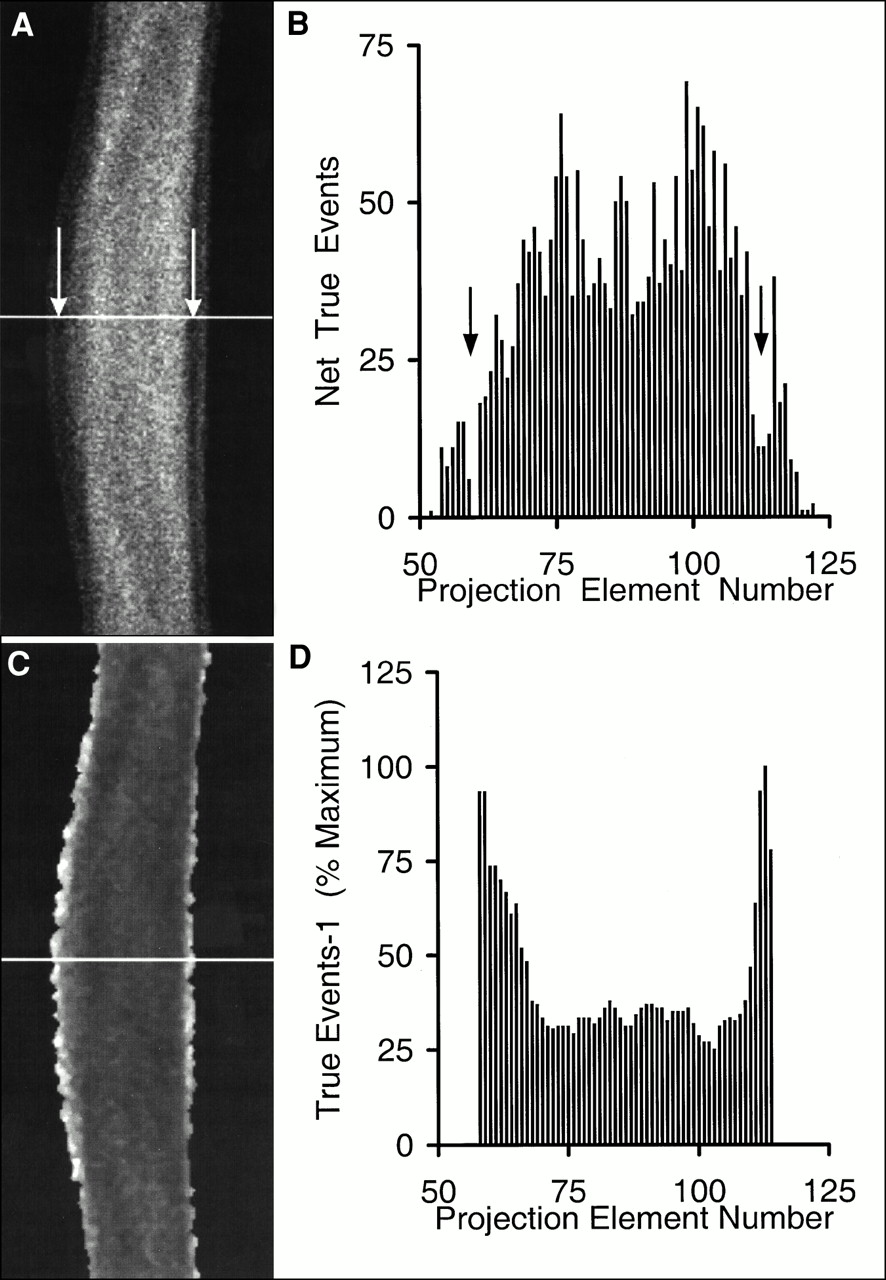
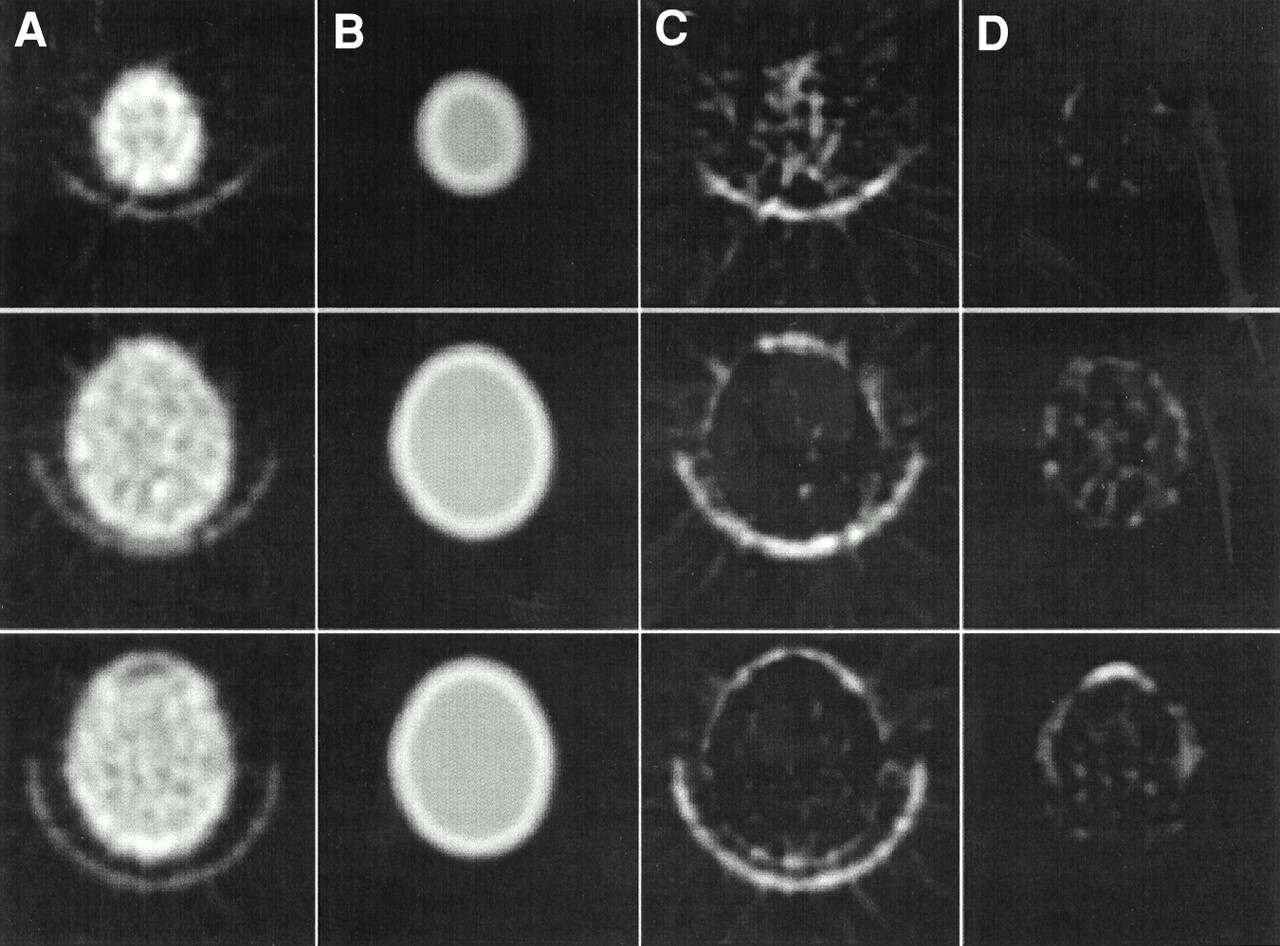
Our method is based on measured emission blood flow scan data. In a parallel-ray projection set (sinogram) of a transverse section of a human head, bands of reduced activity are present between the brain and scalp (Figs. 1A and B). These bands are a result of low perfusion of the skull relative to perfusion of the brain and scalp. Our method uses the position and thickness of these bands to estimate the position and thickness of the skull. This information is used to construct an attenuation coefficient map for correction of emission data. The process of identifying the skull and generating attenuation correction factors consists of identifying the extracranial (scalp activity) peaks in each sinogram projection profile and masking ray sums that do not pass through the head, generating a reciprocal of the masked sinogram to artificially enhance the skull, filtered backprojection of the reciprocal sinogram to form a skull image, extracting profiles across the skull image, and fitting a mathematic model to the skull profiles for generation of attenuation correction factors. Each of these steps is described below.

Emission sinogram (A) and single projection profile (B) taken at position of white line. Arrows denote bands of reduced activity. Shown are reciprocal of masked emission sinogram (C) and profile (D) taken at position of white line.
Mask Data Outside Peak Extracranial Activity.
The first step in this process is to find the peaks of the extracranial activity using thresholds and derivatives and then to mask data outside these peaks. To quantify background noise, the mean and SD of the first 11 ray sums (across all projection angles) are calculated for each sinogram plane. Each sinogram is smoothed with a five ray-sum by five projection-angle median filter to reduce noise. The kernel sizes of the various median filters used throughout the algorithm were determined empirically and were as small as possible to achieve the desired noise reduction necessary to improve the robustness of each step. A crude mask of the sinogram is generated by assigning unit value to all bins >2 SDs above the background mean. The mask for each plane is smoothed with a five ray-sum by five projection-angle median filter to reduce holes and islands without distorting the edges. The crude mask is applied to the original sinogram, resulting in a sinogram with unprocessed data within the boundaries of the extracranial activity and zero background outside the head. To more accurately find the peak of extracranial activity, numeric derivatives are calculated. Most emission sinogram projections contain a discrete extracranial peak separated from the brain activity by a discrete minimum. Therefore, the first zero crossover of the first derivative corresponds to the location of the peak. However, some projections do not contain a discrete minimum and, as a result, the first derivative does not cross zero at the near edge of the head (3). The second zero crossover of the absolute value of the first derivative was found to be a more robust indicator of the peak of extracranial activity because it corresponds exactly to the first zero crossover of the first derivative when a discrete peak is present and, in cases in which a minimum is not present, it corresponds to the minimum of the first derivative, which is only a few millimeters deep to the buried peak (3). The first derivative is taken across the ray sums of each projection and some smoothing is performed across projection angles using a convolution kernel (Table 1). After taking the absolute value of the first derivative, the second derivative is calculated through a second convolution with the same kernel. The peak of extracranial activity on each projection profile is located by scanning the second derivative and finding the second zero crossover from either end. The location of the peak (bin number) is recorded as a function of projection angle to generate an edge curve for each side of the sinogram. The two extracranial peak edge curves are smoothed with a median-of-three filter. An accurate mask sinogram is formed by assigning unit value to all bins between the smoothed edge curves.
Differentiation and Smoothing Kernel
Reciprocal Sinogram.
After the mask is applied, the reciprocal of the masked sinogram is calculated. Reciprocal sinogram values are maximal in the region between the brain and extracranial tissue (Figs. 1C and D). Each reciprocal sinogram plane is smoothed with a three ray-sum by three projection-angle median filter to reduce outlying values without significantly distorting the edges.
Reconstruct Reciprocal Sinogram.
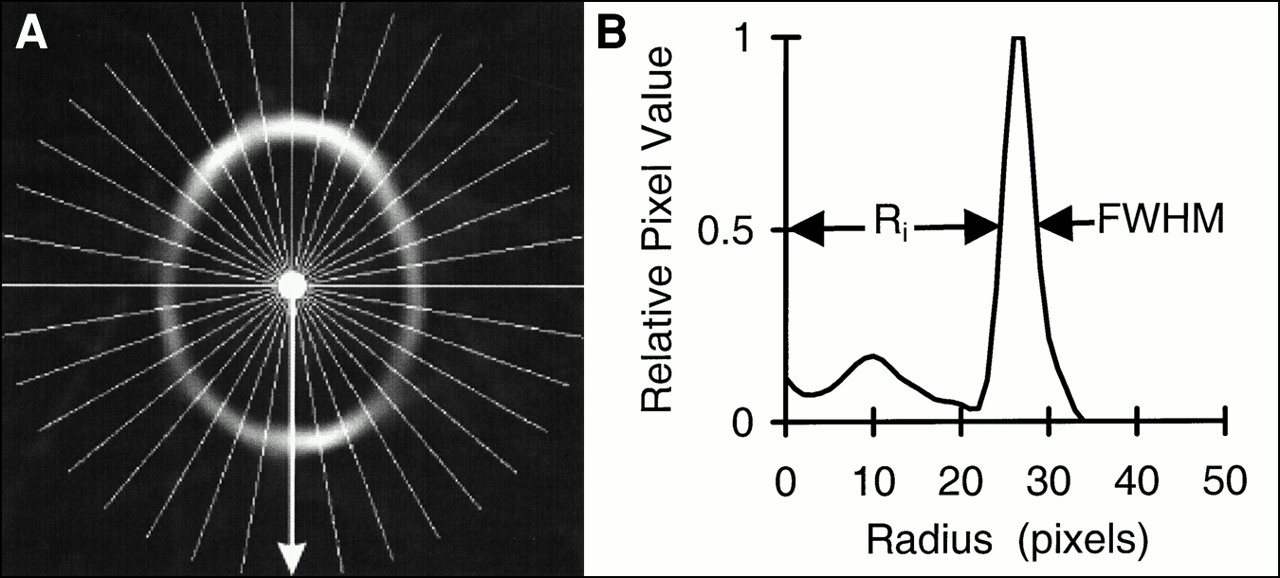
Filtered backprojection (pixel size = detector spacing; x and y pixel dimensions = number of ray sums per projection; Hanning filter cutoff, 1.12 cycles/cm or 0.35 cycle/projection) of the reciprocal sinogram results in an image that represents the skull (Fig. 2A). This image is not a true image of the skull, but it contains information about the position and thickness of the space occupied by the skull.
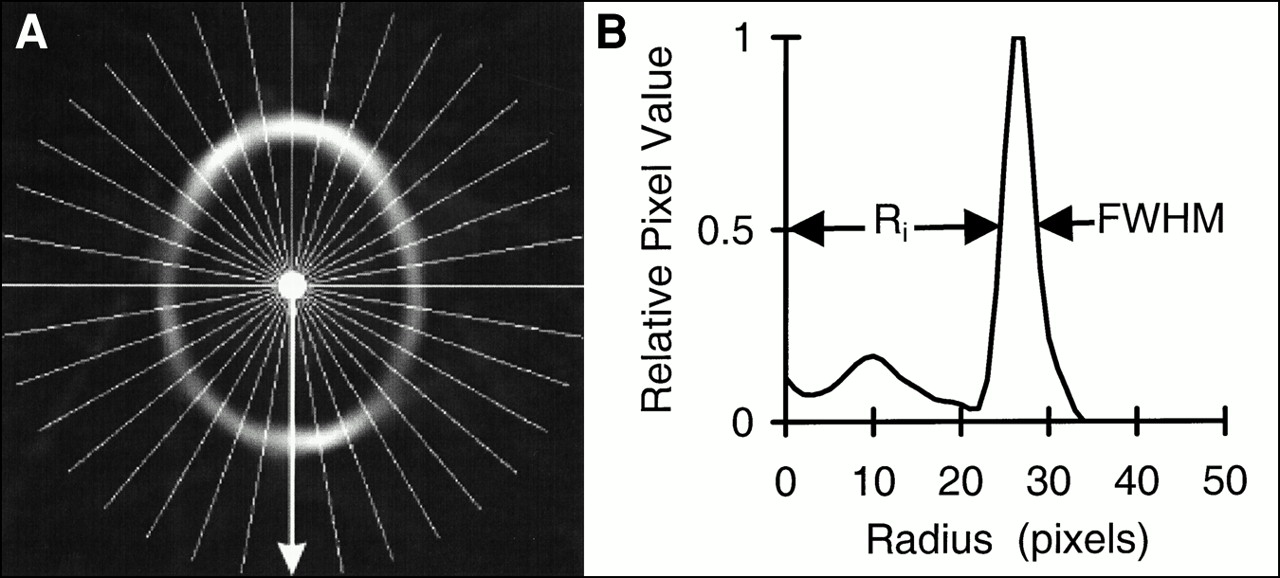
(A) Skull image generated through filtered backprojection of reciprocal sinogram with white lines representing position of 36 profiles. (B) Profile taken at position of arrow. Inside radius (Ri) and full width at half maximum (FWHM) are labeled.
Skull Image Profiles.
For each plane of the image, the approximate center is estimated in each dimension by collapsing the image in the other dimension, smoothing the resulting projection profile twice with a median-of-seven filter, and determining the midpoint between the outside points at which the profile is half maximal. Thirty-six profiles (one every 10° about the center) are extracted from each skull image plane. After each profile (Fig. 2B) is smoothed with a median-of-three filter and is interpolated onto a fine grid (10 points per original interval), the radii to the inner and outer points on the peak at which the value is half maximal are determined. The average radius and the half width at half maximum (HWHM) are calculated from the inner and outer radii for each profile. Within each plane, high-frequency variations in the radius and thickness of the skull are not expected. To reduce random discontinuous variations, average radius and HWHM values for each plane are filtered. Average radius values are smoothed with a median-of-three filter and a fourth-order Butterworth low-pass filter (cutoff = π/6); HWHM values are smoothed with a median-of-five filter and a fourth-order Butterworth low-pass filter (cutoff = π). New inner radius (Ri) values are calculated by subtracting smoothed HWHM values from smoothed average radius values for each profile.
Attenuation Model.
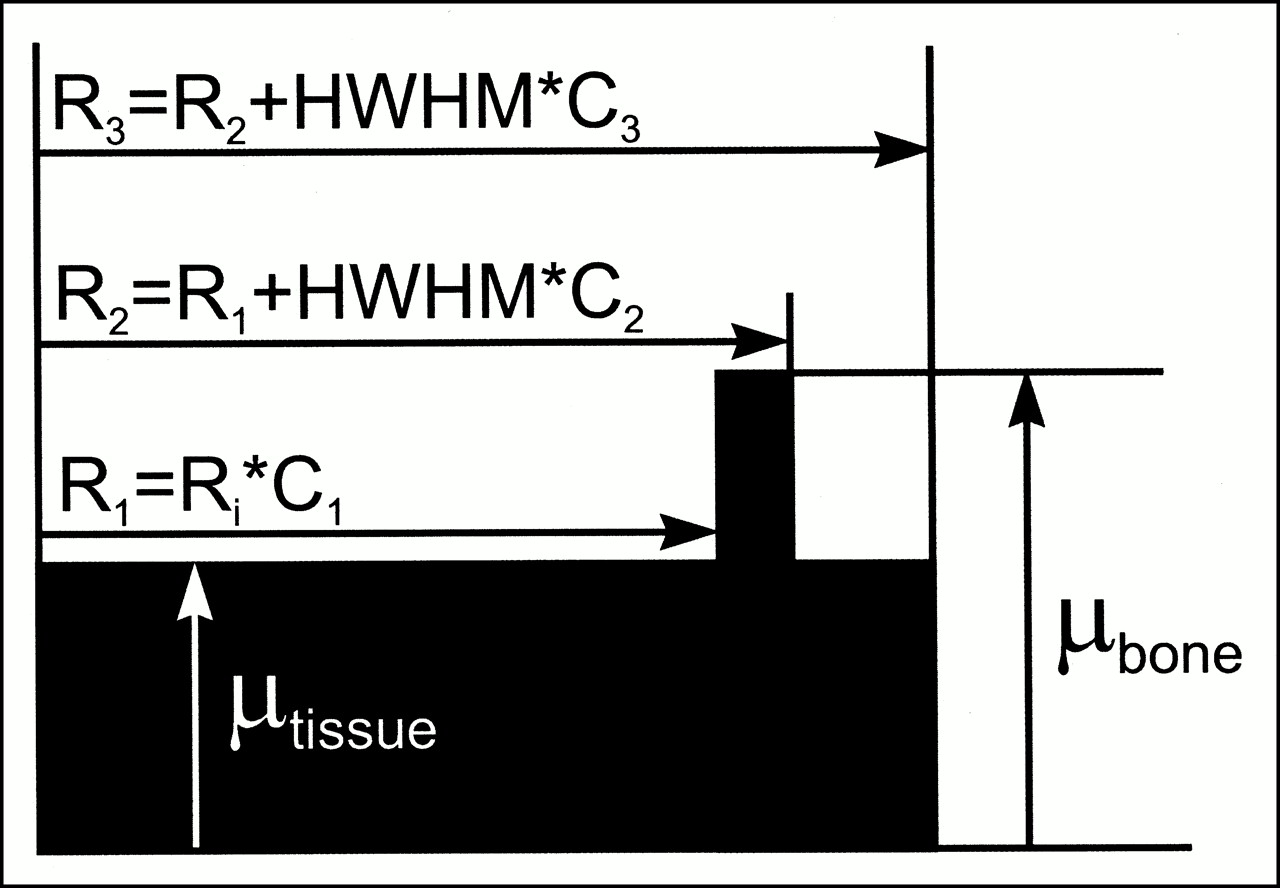
The attenuation model (Fig. 3) describes the head as a combination of continuous regions representing brain, skull, and extracranial tissue, the dimensions of which are determined by scaling Ri and HWHM values for each profile. Model scale constants (C1, C2, and C3) and attenuation coefficients (μtissue and μbone) are determined empirically from measured transmission data from several subjects as described below. By filling the polygons defined by R1, R2, and R3 with the appropriate attenuation coefficients and smoothing with a two-dimensional Gaussian blurring function (6-mm full width at half maximum [FWHM]), two-dimensional attenuation images are generated for each plane (Fig. 4A).

Attenuation model profile comprises brain, skull, and scalp, dimensions of which are determined by Ri and thickness (HWHM) of skull multiplied by scale constants. Attenuation values in model are set to attenuation coefficient (μ) for tissue from radius 0 to R1, μ for bone from R1 to R2, and μ for tissue from R2 to R3. R1 = Ri × constant C1, thickness of bone = HWHM × constant C2, and thickness of extracranial tissue = HWHM × constant C3. Model is then smoothed with Gaussian blurring function (6-mm full width at half maximum) that approximates resolution of scanner.
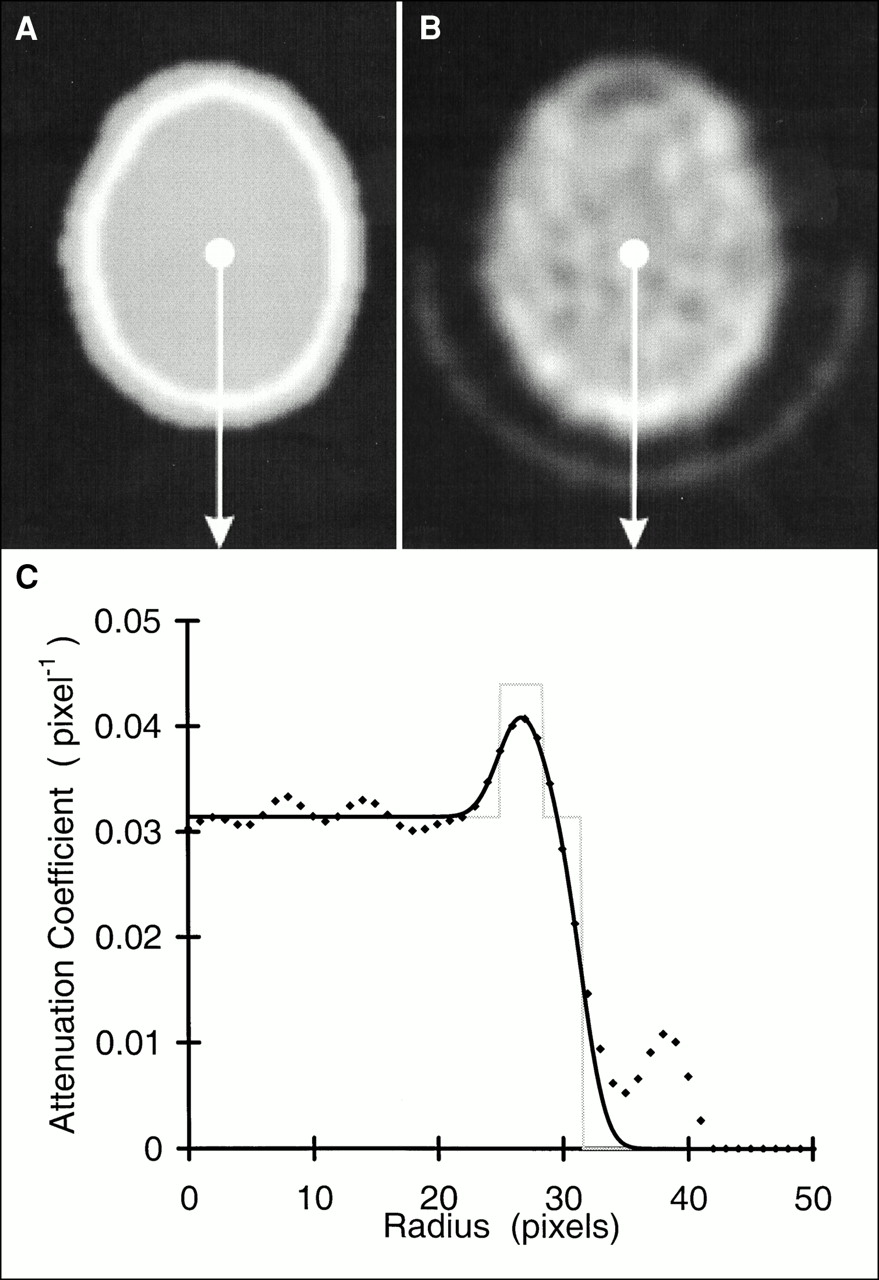
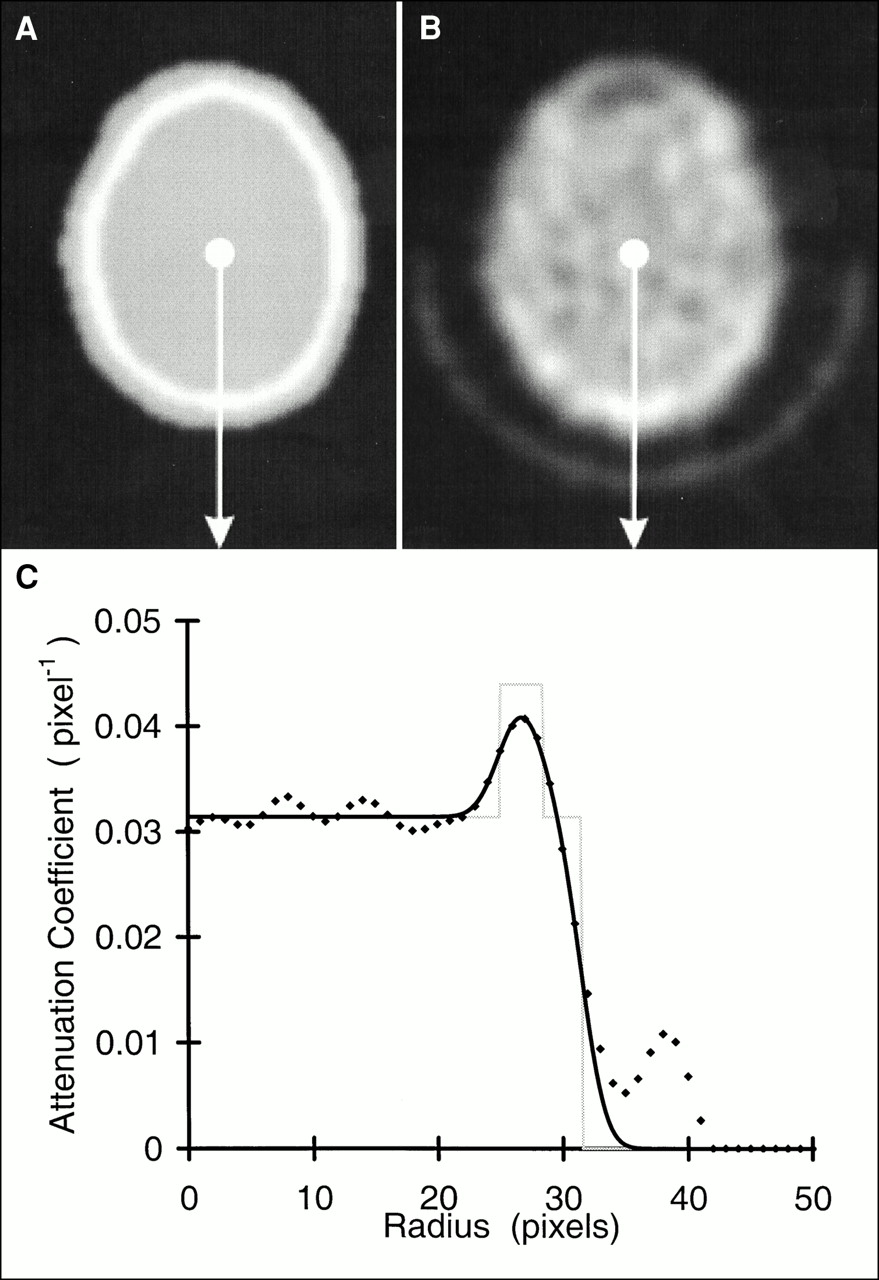
Attenuation model image (A), measured transmission image (B), and profile plots (C) taken at position of arrows in A and B. Smoothed and unsmoothed model profiles (solid and dotted lines) are shown with corresponding measured transmission profile (♦).
Attenuation Image Averaging.
All attenuation images for a given subject are realigned to the attenuation image from the first study with software developed in our laboratory that uses Newton’s method to search for rotational and translational parameter values (six degrees of freedom) that minimize the mean squared error between the reference and overlay volume (4). These registered images are averaged. New attenuation images are generated for each study by rotating and translating the average attenuation image to the original frames of reference. Each attenuation image is then multiplied by the pixel size, forward projected, and converted to attenuation correction factors by taking the inverse natural logarithm.
Data Acquisition and Processing
All procedures were in accordance with the ethical standards of the institutional review board of Indiana University. Data were acquired using an ECAT 951/31R (Siemens Medical Systems, Inc., Hoffman Estates, IL). This tomograph has a 10.8-cm axial field of view comprising 16 true planes and 15 cross planes with interplane septa extended (two-dimensional mode). It is equipped with three rotating 68Ge rod sources (37–118 MBq each) for measured transmission measurements. After giving informed consent, healthy, right-handed volunteers (n = 10) were positioned in the tomograph. The inferior edge of the field of view was aligned ∼1 cm above and parallel to the canthomeatal line. Head motion was limited by a forehead strap and vacuum pillow (n = 5) or by a thermoplastic face mask (n = 5). A 111-million-count transmission scan (SD, 17 million) of each subject’s head was acquired to be used with a 668-million-count blank scan (SD, 102 million) for calibration of the calculated attenuation correction method. Subjects either rested quietly or listened to auditory stimuli presented monaurally (right side) through headphones throughout a series of eight emission scans. Only a single resting baseline scan was acquired. Therefore, only a single auditory activation scan, unrelated spoken English words, was used to create an activation image. Although only one baseline and one auditory stimulation scan were used for the activation image, attenuation correction factors were calculated for all eight scans of each subject using the automated method. Further details of the stimuli are beyond the scope of this article. Dynamic sinograms were acquired during the injection of a bolus of ∼1850 MBq (50 mCi) 15O-labeled water. A single 90-s frame, beginning when the rising edge of the tissue curve reached 75% of its maximum, was integrated from each 27-frame (16 × 5 s, 4 × 10 s, 4 × 30 s, 3 × 120 s) dynamic sinogram. The resulting sinograms were 192 ray sums by 256 projection angles by 31 planes. Emission data were corrected for random coincidence events, dead time, and detector efficiency. Images were reconstructed with software developed in our laboratory (5) that uses Huesman’s method (6) to generate mean and variance values for circular regions of interest (1 cm2) centered about every pixel in image space. Statistical activation images of Z values were created by dividing the difference of mean images (activation minus baseline) by the square root of the sum of the variance images. Data were analyzed on a Hewlett-Packard 9000/755 workstation (Hewlett-Packard, Andover, MA) operating at 125 MHz with 512-MB random access memory. The main program and most subroutines were written in Interactive Data Language ([IDL] Version 4; Research Systems, Inc., Boulder, CO). Computationally intensive algorithms were implemented in C and called from the main program.
Model Fitting
To establish scale constants (C1, C2, and C3) and attenuation coefficient values (μtissue and μbone) in the attenuation model, the model (Fig. 3) was fit to profiles generated from measured transmission images of the subjects studied (Fig. 4). The measured transmission images were reconstructed using filtered backprojection (pixel size = detector spacing; x and y pixel dimensions = number of ray sums per projection; Hanning filter cutoff, 1.12 cycles/cm or 0.35 cycle/projection) of the natural logarithm of the ratio of the transmission sinogram to the blank sinogram. Both transmission and blank sinograms were smoothed with a two-dimensional filter (3.5 ray sums × 3.5 angles; 1.1 cm × 2.5° FWHM) before processing to reduce noise in the transmission images. The one-dimensional model function was fit to measured transmission profiles, extracted from exactly the same positions as the skull image profiles, using the nonlinear regression algorithm of Marquardt as published by Bevington (7) and implemented in the IDL library routine “curvefit.” Data in the tails of the profile were masked to obtain a good fit to the data within the head. Each measured transmission profile was preprocessed to separate the head holder from the data within the head. In this process, the profile was smoothed with a median-of-five filter. All values below 10% of the maximum of the smoothed profile were set to zero to reduce background noise. The first derivative was taken, with respect to the radius from the center, through convolution of each profile with a kernel consisting of [−1, 0, 1]. The first derivative was then smoothed with a median-of-three filter. An outside-edge mask was generated by assigning unit value to all points of the smoothed first derivative that were ≤50% of the minimum of the smoothed first derivative curve. This mask was applied to the smoothed measured transmission profile. With the location of the maximum taken as the starting point, the resulting curve was scanned outward until its value was <50% of the maximum. This point was taken as the approximate edge of the head. Unit weight was assigned to the points inside the head and to the points well outside the head with values below 10% of the maximum, which were previously set to zero; zero weight was assigned to the points in the scatter-tail and head-holder region of the profiles.
Model Validation
The attenuation model was fitted to the measured transmission data to obtain a set of individual model parameters for each subject (pi). To validate the attenuation model, the subjects were divided into two equal groups (A and B). The individual model parameters were averaged for group A (pA). The usefulness of the mean parameter estimates as a substitute for individual parameter estimates was evaluated by comparing mean-squared-error values between measured transmission images and attenuation model images in group A using individual parameter estimates (gA:pi) and group A mean parameter estimates (gA:pA). To evaluate whether mean fitted parameters from a small group could be used for other subjects without further fitting, group A mean model parameters were used to generate attenuation coefficient images for the second group of subjects (group B), and the results were compared with the measured transmission images in these subjects by calculating mean-squared-error values (gB:pA). As a point of reference, mean-squared-error values were also calculated between measured transmission images and homogeneous ellipses that were fitted manually, by an experienced PET technologist using ECAT software, to the first emission image for each subject in group A. The null hypothesis that the mean-squared-error values between measured transmission images and calculated attenuation images were equal for all methods (individual parameters, same group mean parameters, different group mean parameters, and manual ellipses) was tested with one-tailed t tests. Difference images between the automated calculated attenuation coefficient images and the measured attenuation coefficient images were used to examine error and bias.
Activation Maps
Blood flow images corrected with our calculated attenuation factors were compared with images corrected with measured transmission factors in data from an auditory activation paradigm to demonstrate the advantage of the new approach. A comparison of Z values in the auditory cortex was used as a measure of the relative performance of each image reconstruction method.
RESULTS
Model Fitting
The mean attenuation model parameter estimates for groups A and B are presented in Table 2.
Best-Fit Model Parameters Obtained by Fitting Attenuation Model to Measured Transmission Profiles
Model Validation
The mean-squared-error values between the calculated attenuation and measured transmission maps are presented in Figure 5. The difference between the mean-squared-error values for groups A and B was not significant (P > 0.8). The error for the automated method was significantly lower than the error for the ellipse method (P < 0.001). This finding shows that mean parameters from a small group may be used for other subjects and that this method is more accurate than the ellipse method. The difference image (Fig. 6) reveals that the largest residuals are attributable to the thermoplastic mask, the head holder, and the frontal sinus because they were not included in the model.
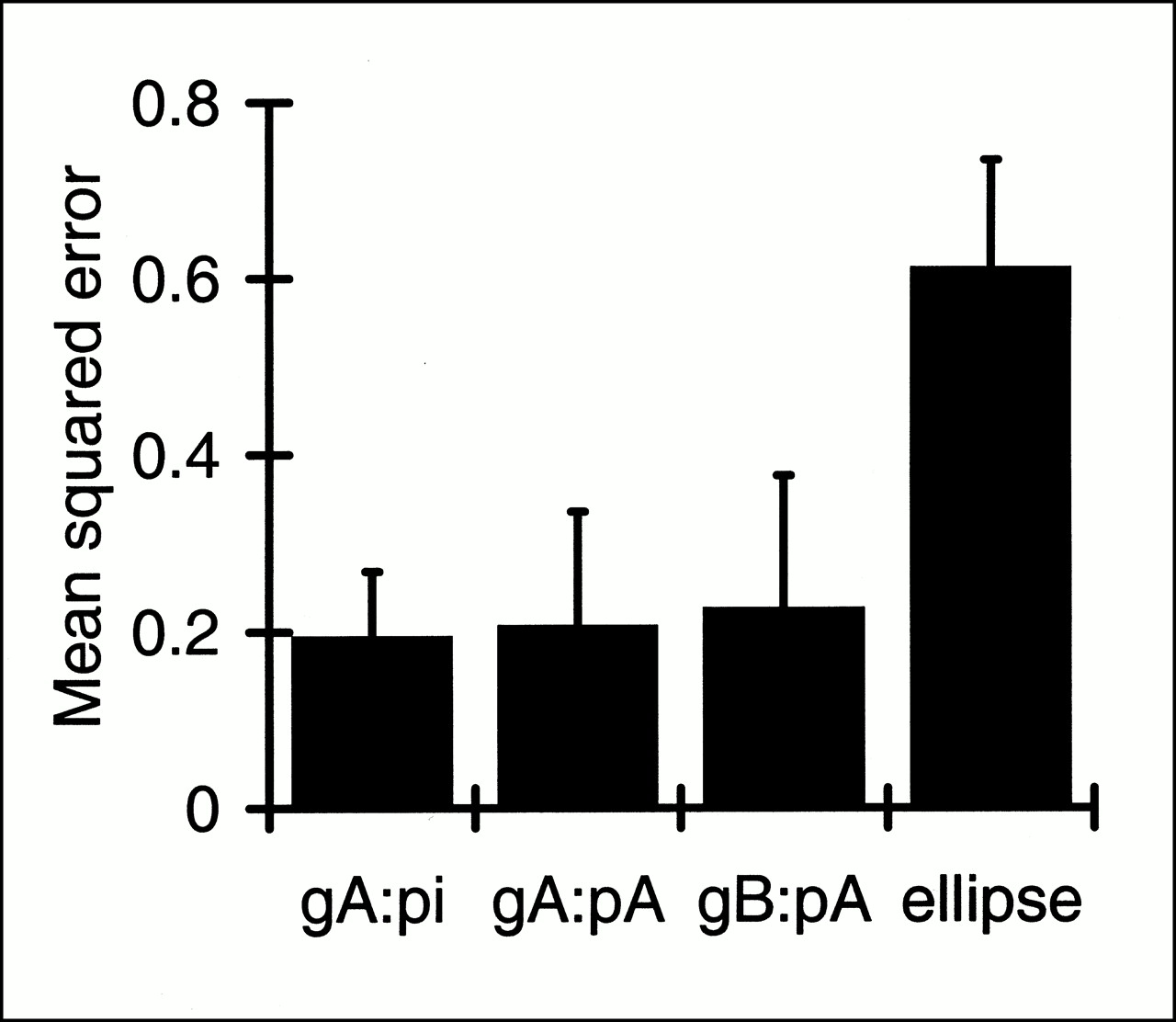
Comparison between calculated and measured attenuation correction methods. Each column represents mean-squared-error values, averaged across group of subjects, between individual measured transmission images and calculated attenuation images. Error bars represent SD. GA:pi = error for group A using individual fitted parameters, gA:pA = error for group A using group A mean parameters, gB:pA = error for group B using group A mean parameters, and ellipse = error for manually fitted homogeneous ellipses. Only error for ellipse method differed significantly (P < 0.001).

Three planes (superior, middle, and inferior) of measured transmission image (A) and attenuation model image (B). Difference images were generated by subtracting A minus B (C) and B minus A (D) and displaying only positive values. Largest residuals are attributed to head holder and frontal sinus because they were not included in model.
Activation Maps
A comparison of auditory activation images in a single subject is depicted in Figure 7. The reduction of noise with the calculated method results in a higher maximum Z value in the auditory cortex (4.2 vs. 3.7) and a visibly larger region of activation. Also notice that the base blood flow images appear to be of higher quality and to have fewer artifacts with the calculated method compared with the images obtained with the measured method.
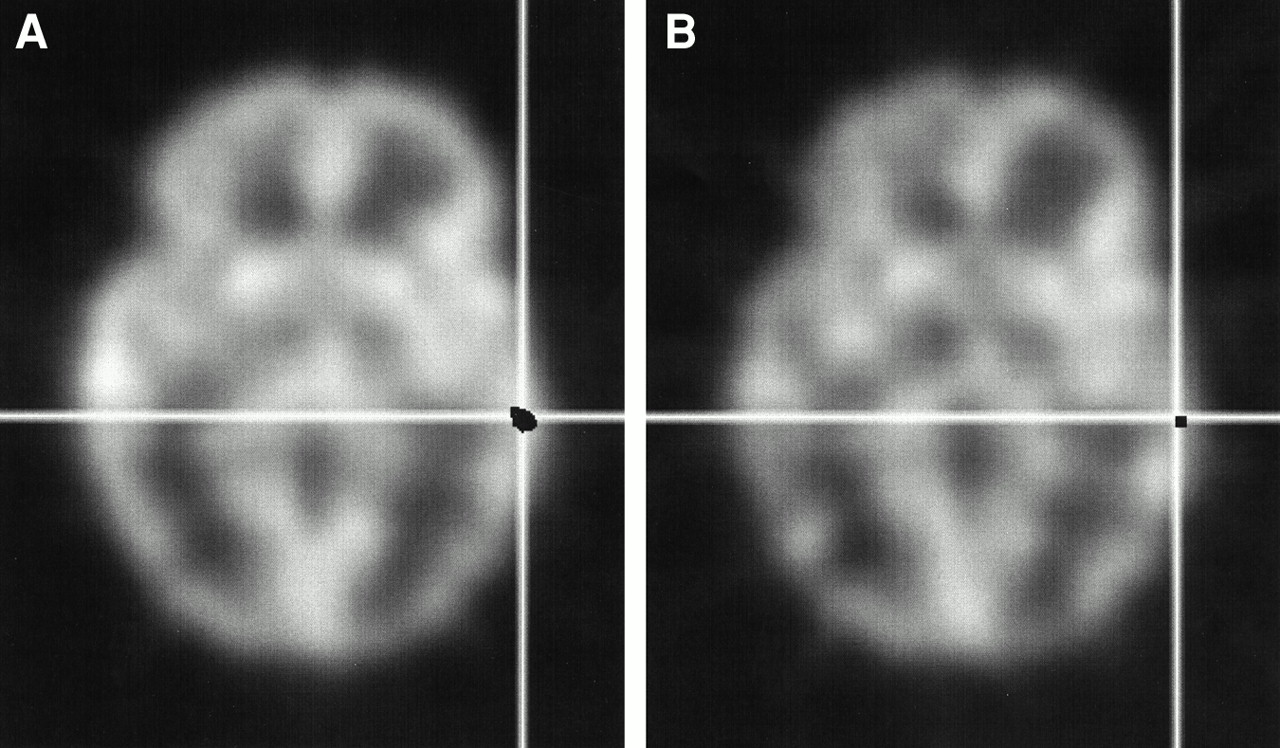
Comparison of auditory activation images for single subject. Blood flow images corrected with automated calculated method (A) appear to be of higher quality than those corrected with measured method (B). Activation Z images, at threshold of 3.3 and superimposed in black, reveal that reduction in variance results in higher maximum Z value (4.2 vs. 3.7) and visibly larger region of activation in auditory cortex.
Run Time
Starting with the integrated unmashed sinogram, the entire process takes ∼30 min for each scan, using routines that have not been optimized for speed. Parameter fitting, which needs to be performed for only a few subjects, takes ∼3 h for each subject.
DISCUSSION
We have developed an automated method for calculation of attenuation correction factors based on emission sinogram data. Our technique compensates for subject motion by deriving each set of correction factors from the corresponding emission study. Although the model parameters were tuned with measured transmission data from several subjects, it was shown that fitted parameters from a small group could be used for other subjects, without further fitting, allowing the elimination of measured transmission scans. The method reduced emission image variance by eliminating noise propagation from count-limited transmission data. This reduction of noise resulted in a higher maximum Z value in activation images. The elimination of measured transmission scans has the added advantage of a reduction in scan time (∼15 min) and radiation exposure (∼0.5–1.6 mrem).
Most calculated attenuation methods do not include the frontal sinus or the head holder. Our model is no exception. The size and shape of the frontal sinus are highly variable. The exact position of the acrylic head holder, being somewhat flexible, is difficult to reproduce as well. The only way to accurately represent these two features for each individual is through measured transmission measurements. We believe that it is more important to apply identical low-variance attenuation correction factors, adjusted for subject motion, to each study. Our method requires relatively high tracer uptake in superficial tissues, which precludes testing of the method with standard attenuation phantom studies. The sensitivity of this method to subject motion was not specifically addressed in this study because it was tested retrospectively on data that did not contain gross subject motion. Our method requires an additional 30 min of computation for each scan. Although this may seem excessive, our routines are automated to process all scans for a subject without user intervention. In addition, our routines have not been optimized for speed. With software optimization, we expect that this time can be reduced to a few minutes per study. We showed that standard parameter values from a small group could be used for future studies without further fitting. However, factors such as sex, ethnic group, and extremes of age are potential sources of inaccuracy that have yet to be investigated. We do not anticipate significant errors caused by these factors relative to the reduction in error achieved by eliminating the measured transmission scan.
We anticipate that this two-dimensional method could be adapted for use in three-dimensional PET imaging. Two-dimensional attenuation correction methods have been used for three-dimensional PET since its inception (8) and are still being used (9) because of the complications of three-dimensional transmission scans and the redundancy of fully three-dimensional calculated methods. Likewise, our method could be used to generate a calculated attenuation volume for three-dimensional PET after Fourier rebinning of three-dimensional emission data to two-dimensional sinograms. Simply substituting three-dimensional forward projection for the current two-dimensional forward projection of the calculated attenuation volume would produce three-dimensional attenuation correction factors. Of course, recalibration of the model parameters would be required for three-dimensional implementation, as it should be for different tracers, tracer delivery methods, acquisition protocols, or PET cameras.
To overcome the limitations of measured transmission attenuation correction in activation studies, several strategies have been used with varying degrees of success. The simplest of these strategies is smoothing of the transmission data with a one-dimensional (10) or two-dimensional (11) Gaussian filter before calculation of the attenuation correction factors. Another simple method involves backprojection of the transmission data followed by forward projection of the resulting image (12–14). This method, known as reconstruction–reprojection, has been shown to degrade image quality in some cases (15). To overcome this degradation at low counting rates, some investigators (16–19) have suggested segmenting the reconstructed transmission images into areas with significantly different attenuation coefficients and reassigning uniform attenuation to these areas before reprojection. Although these methods may reduce noise, they still require transmission scans and they fail to correct for patient motion. Andersson et al. (14) proposed reconstructing emission images without attenuation correction, aligning later scans with the first scan (which is assumed to be in the same orientation as the transmission scan), and applying the inverted registration parameters to the reconstructed transmission image before reprojection. Although this method does correct for patient motion, it still requires a transmission scan and it suffers from possible image degradation at low counting rates (15). Alternatively, attenuation correction factors may be calculated by locating the object boundaries in the emission data, assigning typical attenuation coefficients, and forward projecting attenuation images. Calculated attenuation correction methods are used widely (3,20–24) because they reduce scan duration, radiation dose, finite width approximation effects, and statistical noise propagation. The most straightforward of these methods (20,21) involve reconstructing emission images without attenuation correction and manually fitting ellipses about the head to define the contour. Such simple geometric methods require excessive user intervention in addition to other problems. More recently, automated methods (3,22–24) have been used to estimate object contours through backprojection of the emission sinogram borders. These methods use thresholds or derivatives (or both) to locate the sinogram border and then fill the contour with soft-tissue attenuation surrounded by a uniformly thick layer of bone attenuation. These emission sinogram–based methods avoid pitfalls associated with measured transmission attenuation correction, but skull and extracranial tissue thickness are not uniform. Such mismatches in attenuation medium are known to introduce inaccuracies in processed images (1). Another class of emission sinogram–based methods attempts to estimate attenuation coefficients directly from the emission data by iterative inversion of the forward mathematic model. A summary of these methods is beyond the scope of this article, but Nuyts et al. (25), in a recent publication in this area, conclude that the problem of simultaneous maximum-likelihood reconstruction of attenuation and activity is highly underdetermined and without a single maximum, resulting in considerable crosstalk between the activity and attenuation images.
Several features are unique to our approach: using the reciprocal of each emission sinogram to allow the attenuation model to compensate for skull and scalp thickness variations, even in more superior sections where their thickness is disproportionately increased because of the oblique nature of the section; and averaging all attenuation images after coregistration and then returning the average image to the original frames of reference before generating attenuation correction factors to ensure that the same factors are applied to all images while compensating for patient motion.
CONCLUSION
We have developed an automated attenuation correction method that compensates for subject motion between scans, accurately reproduces the characteristics of the head, and eliminates the use of measured transmission data to reduce scan duration, statistical noise, and radiation dose.
Acknowledgments
This work was supported in part by National Institutes of Health grant P20 CA86350, Indiana 21st Century Fund, and a fellowship from the Radiological Society of North America Research and Education Fund.
Footnotes
Received Apr. 5, 2000; revision accepted Nov. 10, 2000.
For correspondence or reprints contact: Gary D. Hutchins, PhD, Imaging Science Division, Department of Radiology, Indiana University School of Medicine, 541 Clinical Dr., Rm. 157, Indianapolis, IN 46202-5111.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}