


Abstract
2587
Introduction: Owing to the high level of overexpression in prostate cancer cells, prostate-specific membrane antigen (PSMA) represents a viable diagnostic and therapeutic target in prostate cancer. Despite the clinical efficacy of PSMA-radioligand therapy (PRLT), xerostomia and xerophthalmia caused by salivary and lacrimal gland (SLG) impairment are a dose-limiting side effect of PRLT. Estimating the radiation dose using radiopharmaceutical uptake in the SLGs from PET/CT images prior to treatment could help choose the optimal, personalized administered activity to avoid severe side effects, or predict their occurrence. However, quantifying SLG uptake on PET usually requires manual segmentation, which is labor-intensive. To that end, we aimed to utilize deep neural nets to automate SLG segmentation on [18F]-DCFPyL (PSMA) PET images. We compared the effectiveness of networks with single (PET) vs. multi-modality (PET & CT) inputs.
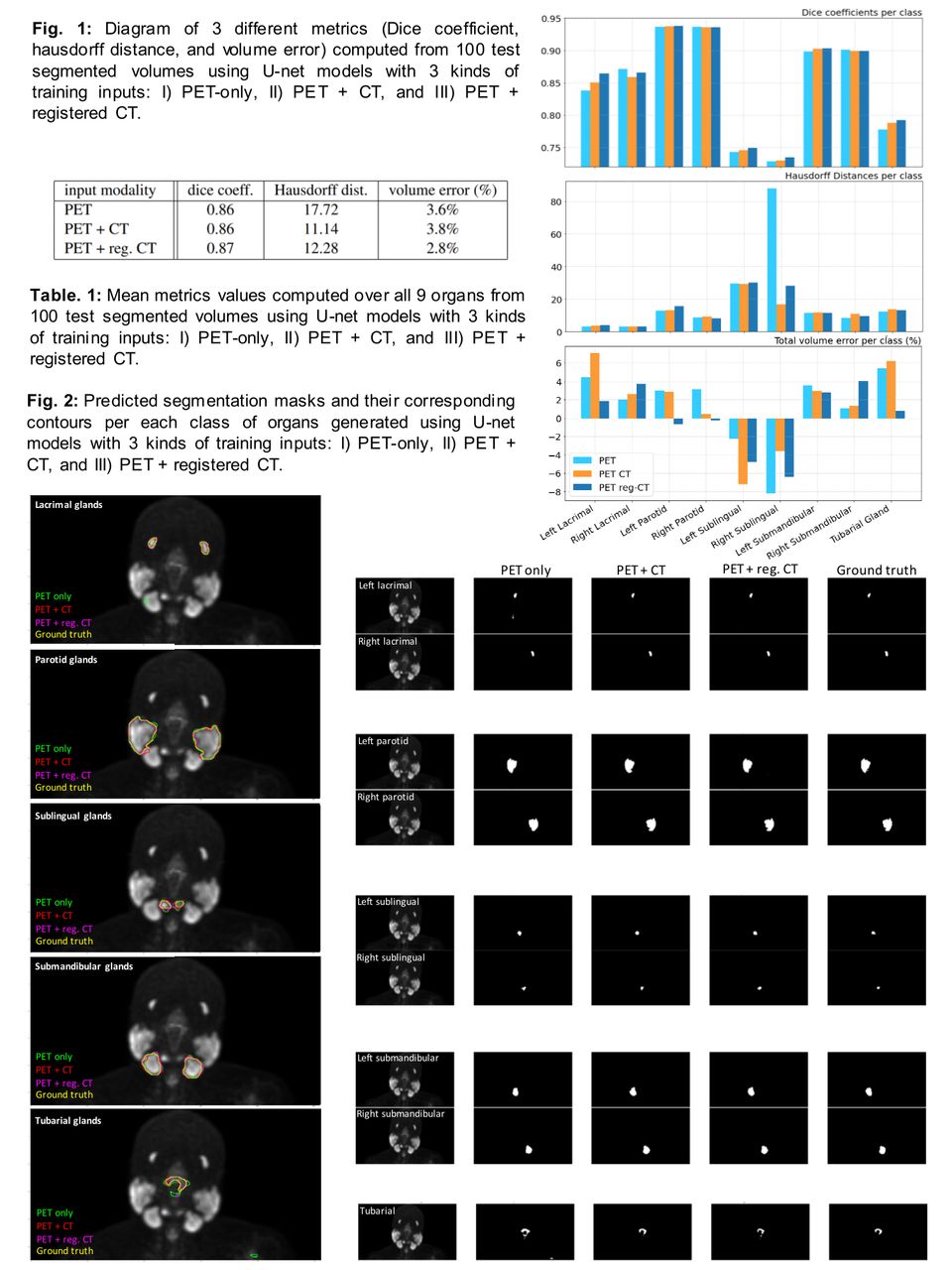
Methods: Predicted segmentations generated by all U-Nets trained on 3 different modalities demonstrated high quality result. (Fig.2). The average Dice score on 100 test cases over all 9 classes (glands) was 0.86 for the model trained on PET only images, and the model using PET and CT images. It was slightly higher at 0.87 for the model trained on PET and registered CT images (Table1). The lowest Dice score was for right and left sublingual glands, and the highest for the parotids (Fig.1). The lowest HD was achieved for both multi-modality trained segmentation models (11.14 for PET CT and 12.28 for PET reg. CT) and highest for single modality U-Net (17.72). Right and left sublingual glands had the highest HD, while the highest value was obtained by PET modality trained network, suggesting good localization of the multi-modality trained U-net. For overall volume error(%), PET and registered input U-Net performed best (2.8%). Overall, our results demonstrate the higher performance of automated segmentation model trained on multi-modality registered images compared to the model trained on single-modality (PET) image, suggesting that the added modality (CT) provides complementary information, leading to better localization of the organs.
Results: Predicted segmentations generated by all 3 U-Nets demonstrated high quality result. (Fig.2). The average Dice score on 100 test cases over all 9 classes (glands) was 0.86 for the model trained on PET only images, and on PET and CT images. It was slightly higher at 0.87 for the model trained on PET and registered CT images (Table1). The lowest Dice score was for right and left sublingual glands, and the highest for the parotids (Fig.1). The lowest HD was achieved for both multi-modality trained segmentation models (11.14 for PET CT and 12.28 for PET reg. CT) and highest for single modality U-Net (17.72). The highest HD value was obtained by PET modality U-net, suggesting good localization of the multi-modality trained U-nets. For overall volume error(%), PET and registered CT U-Net performed best (2.8%). Our results demonstrate higher performance of the model trained on multi-modality registered images compared to single-modality (PET) image, suggesting that added modality (CT) provides complementary information, causing better localization of the organs.
Conclusions: Our results illustrate the ability of deep convnets, trained on large-size multi-modality PSMA PET/CT, in SLG segmentation. Our model has the potential to ease up diagnostic or therapeutic tasks that need effective segmentation of radiopharmaceutical-accumulating organs. Visual and quantitative results show the benefit of multi-modality input images to enhance the networks’s localization and classification power. Inspired by that, our future plan is to investigate different modality fusion techniques, and quantifying the effect of image/modality resolution, by down sampling CT to the PET images, and to assess different segmentation models along with 3D segmentations, towards routine deployment of our segmentation model in clinical workflows.

In this issue




{kind=link}
Jump to section
Related Articles
Cited By...
- No citing articles found.